


在现代Web应用中,数据库的读写分离和存算分离是两种常见的优化手段,它们可以显著提高系统的性能和可扩展性,PHP作为广泛使用的服务端脚本语言,可以通过编写特定的类来实现这两种分离策略,下面将分别介绍一个用于实现主从分离的PHP类和一个用于实现存算分离的PHP类。

主从分离类
主从分离是指在数据库架构中,将写操作(如INSERT、UPDATE、DELETE)定向到主数据库服务器,而将读操作(如SELECT)定向到一个或多个从数据库服务器,这种分离可以减轻主库的压力,提高读操作的性能。
PHP主从分离类实现步骤:
1、连接配置:首先需要配置主库和从库的连接信息,包括主机名、端口、用户名、密码以及数据库名。
2、创建连接:根据配置信息,使用PHP的PDO或mysqli扩展创建主库和从库的连接实例。
3、读写判断:对于每个数据库操作请求,判断其是读操作还是写操作。
4、执行操作:如果是写操作,则使用主库连接执行;如果是读操作,则使用从库连接执行。
5、结果处理:获取查询结果或确保写入操作成功执行。
6、异常处理:捕获并处理可能出现的数据库错误。
7、资源释放:操作完成后,关闭数据库连接以释放资源。
代码示例:
class DatabaseMasterSlave
{
protected $master;
protected $slave;
public function __construct($config)
{
$this>connect($config['master'], $config['slave']);
}
public function connect($masterConfig, $slaveConfig)
{
try {
$this>master = new PDO($masterConfig['dsn'], $masterConfig['user'], $masterConfig['password']);
$this>slave = new PDO($slaveConfig['dsn'], $slaveConfig['user'], $slaveConfig['password']);
} catch (PDOException $e) {
// Handle connection error
}
}
public function query($sql)
{
if (preg_match('/^(SELECT|SHOW|DESCRIBE|EXPLAIN|DESC)/i', $sql)) {
return $this>slave>query($sql);
} else {
return $this>master>query($sql);
}
}
public function close()
{
$this>master = null;
$this>slave = null;
}
}
存算分离类
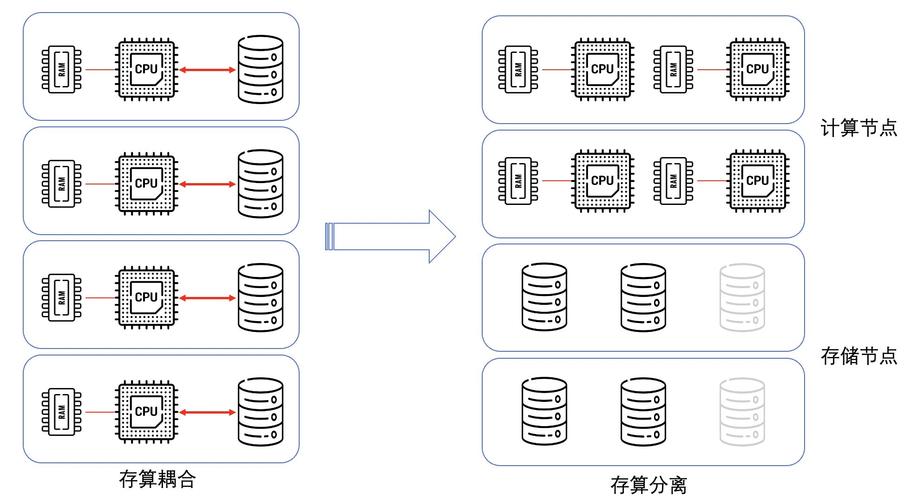
存算分离是指将数据的存储和计算逻辑分开处理,通常用于大数据处理场景,其中数据存储在专门的存储系统中,而计算任务则由计算框架执行。
PHP存算分离类实现步骤:
1、连接配置:配置连接到存储系统和计算框架的信息。
2、数据导入:将数据从存储系统导入到计算框架中。
3、计算任务提交:通过计算框架的API提交计算任务。
4、结果获取:从计算框架获取计算结果。
5、数据处理:对计算结果进行必要的处理,以便在应用中使用。
6、异常处理:处理可能出现的错误,例如网络问题、数据格式错误等。
7、资源释放:关闭与存储系统和计算框架的连接。
代码示例:
class StorageComputeSeparation
{
protected $storageClient;
protected $computeClient;
public function __construct($config)
{
$this>connect($config['storage'], $config['compute']);
}
public function connect($storageConfig, $computeConfig)
{
// Connect to the storage and compute services
}
public function importData($data)
{
// Import data into the compute framework
}
public function submitTask($taskConfig)
{
// Submit a compute task to the framework
}
public function getResults($taskId)
{
// Retrieve the results of a compute task
}
public function processResults($results)
{
// Process the results for use in the application
}
public function close()
{
// Close connections to services
}
}
相关问答FAQs
Q1: 如何确保主从分离中的从库数据与主库保持一致?
A1: 确保主从数据一致通常通过配置MySQL复制来实现,主库上的写操作会自动复制到从库上,定期检查主从同步状态和解决复制延迟问题也是保持数据一致性的关键措施。
Q2: 存算分离中如何处理大规模数据的导入和导出?
A2: 处理大规模数据时,可以使用批量处理和分块技术来减少单次操作的数据量,利用计算框架提供的高效数据导入导出工具,如Hadoop的HDFS命令或Spark的数据读写接口,可以有效地管理大规模数据集。
原创文章,作者:未希,如若转载,请注明出处:https://www.kdun.com/ask/683951.html
本网站发布或转载的文章及图片均来自网络,其原创性以及文中表达的观点和判断不代表本网站。如有问题,请联系客服处理。
发表回复