

环境准备
1、安装Python3
(图片来源网络,侵删)
2、安装机器学习库:scikitlearn、numpy、pandas等
3、安装Jupyter Notebook或其他IDE
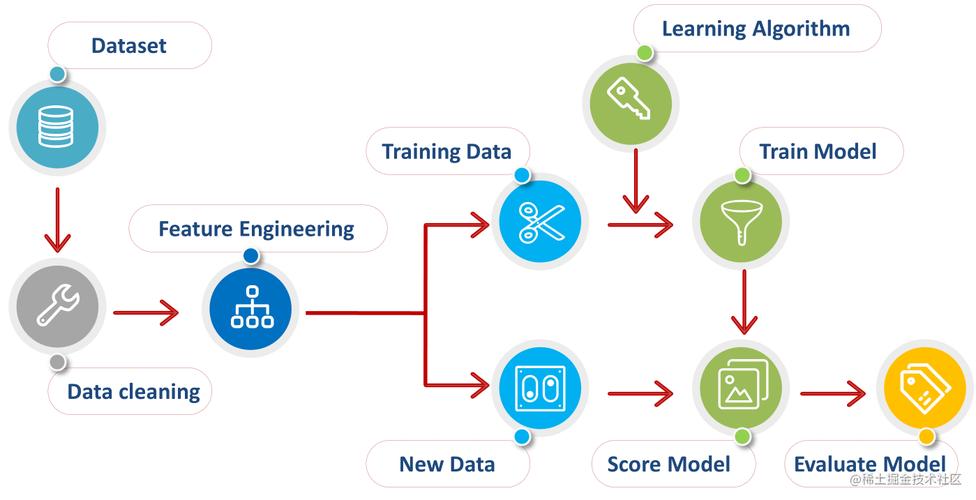
数据预处理
1、数据收集:从网络爬虫、API接口、数据库等获取数据
2、数据清洗:去除空值、重复值、异常值等
3、数据转换:归一化、标准化、独热编码等
4、数据划分:将数据集划分为训练集和测试集
选择模型
1、线性回归:适用于连续值预测问题
2、逻辑回归:适用于二分类问题
3、决策树:适用于分类和回归问题
4、随机森林:适用于分类和回归问题,基于决策树的集成方法
5、支持向量机:适用于分类和回归问题
6、K近邻算法:适用于分类和回归问题
7、神经网络:适用于复杂的非线性问题
训练模型
1、导入模型库
2、创建模型对象
3、拟合模型:使用训练集数据训练模型
4、调整超参数:通过交叉验证等方法寻找最优超参数
评估模型
1、预测:使用训练好的模型对测试集进行预测
2、计算评估指标:准确率、精确率、召回率、F1分数、均方误差等
3、可视化结果:绘制混淆矩阵、ROC曲线等
部署模型
1、保存模型:将训练好的模型保存到文件
2、加载模型:从文件中加载模型
3、应用模型:将新数据输入模型进行预测
案例实践
1、鸢尾花分类:使用决策树、K近邻算法等对鸢尾花数据集进行分类
2、房价预测:使用线性回归、随机森林等对房价数据集进行预测
3、文本分类:使用朴素贝叶斯、支持向量机等对新闻数据集进行分类
4、手写数字识别:使用神经网络对MNIST数据集进行识别
原创文章,作者:未希,如若转载,请注明出处:https://www.kdun.com/ask/680526.html
本网站发布或转载的文章及图片均来自网络,其原创性以及文中表达的观点和判断不代表本网站。如有问题,请联系客服处理。

发表回复