


机器学习端到端场景:从数据准备到模型部署
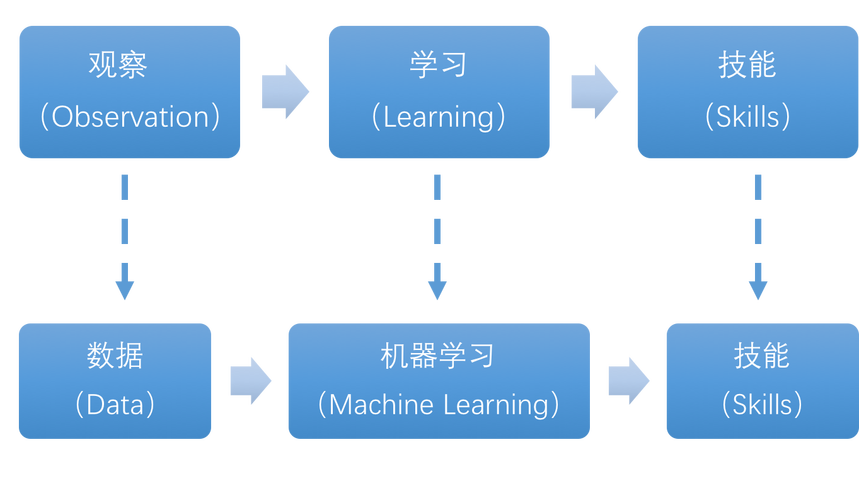

(图片来源网络,侵删)
1. 数据准备与预处理
目标:准备和清洗数据,以便用于训练机器学习模型。
| 步骤 | 描述 |
| 数据收集 | 收集相关数据集,可能来源于公开数据库、APIs、或自定义数据抓取。 |
| 数据清洗 | 去除重复、错误或不相关的数据条目。 |
| 特征选择 | 确定哪些变量(特征)对预测任务最有用。 |
| 数据转换 | 将数据转换为适合机器学习算法的格式,如归一化或标准化数值型特征。 |
| 数据分割 | 将数据分割为训练集、验证集和测试集。 |
2. 模型选择
目标:根据问题类型选择合适的机器学习算法。
| 问题类型 | 推荐算法 |
| 分类 | 决策树、随机森林、支持向量机 (SVM)、神经网络等。 |
| 回归 | 线性回归、岭回归、支持向量回归 (SVR)、神经网络等。 |
| 聚类 | K均值、层次聚类、DBSCAN等。 |
| 异常检测 | 隔离森林、自编码器、LOF算法等。 |
3. 模型训练
目标:使用训练数据来训练选定的机器学习模型。
| 步骤 | 描述 |
| 参数设置 | 设置模型参数,可能包括学习率、正则化系数等。 |
| 交叉验证 | 通过交叉验证评估模型性能,优化模型参数。 |
| 模型训练 | 使用优化后的参数在完整的训练集上训练模型。 |
4. 模型评估
目标:评估模型的性能,确保其在未见数据上的泛化能力。
| 指标 | 描述 |
| 准确率 | 模型正确预测的比例。 |
| 精确度与召回率 | 特别适用于不平衡类别分布的情况。 |
| F1分数 | 精确度与召回率的调和平均。 |
| ROC曲线/AUC | 评估分类模型在不同阈值下的表现。 |
5. 模型优化
目标:通过调整模型参数或选择不同的算法来提高模型性能。
| 方法 | 描述 |
| 网格搜索 | 系统地遍历多种参数组合,寻找最佳模型。 |
| 随机搜索 | 随机选择参数组合进行尝试。 |
| 集成方法 | 结合多个模型的预测以提高整体性能。 |
| 超参数调优 | 使用贝叶斯优化等高级技术寻找最优超参数。 |
6. 模型部署
目标:将训练好的模型部署到生产环境,以供实际使用。
| 步骤 | 描述 |
| API封装 | 创建API接口,使模型能够接收输入并返回预测结果。 |
| 容器化 | 使用Docker等工具将模型及其依赖打包成容器。 |
| 云部署 | 将模型部署到云平台如AWS、Azure或Google Cloud等。 |
| 监控与维护 | 定期检查模型性能,必要时重新训练或调整模型。 |
7. 持续迭代
目标:根据新数据和反馈不断优化模型。
| 步骤 | 描述 |
| 收集反馈 | 从用户或系统获取关于模型性能的反馈。 |
| 数据更新 | 定期更新数据集以反映最新情况。 |
| 模型微调 | 根据新数据调整模型参数或结构。 |
| 性能监控 | 持续监控模型性能,确保其稳定运行。 |
这个端到端的机器学习流程涵盖了从数据准备到模型部署的全过程,每一步都至关重要,以确保最终得到一个高性能、可靠的机器学习系统。
原创文章,作者:未希,如若转载,请注明出处:https://www.kdun.com/ask/675592.html
本网站发布或转载的文章及图片均来自网络,其原创性以及文中表达的观点和判断不代表本网站。如有问题,请联系客服处理。
发表回复