


数学建模与机器学习

在数据分析和人工智能领域,数学建模和机器学习(ML)是两个紧密相关且互补的领域,数学建模涉及使用数学工具和原理来模拟现实世界问题,而机器学习则是通过算法从数据中学习模式和规律,以做出决策或预测。
MLS预置算链概述
MLS(Machine Learning Suite)预置算链是一种集成了多种机器学习算法和数据处理工具的软件框架,它旨在简化机器学习流程,使用户能够快速搭建、训练和部署模型。
使用MLS进行机器学习建模的步骤
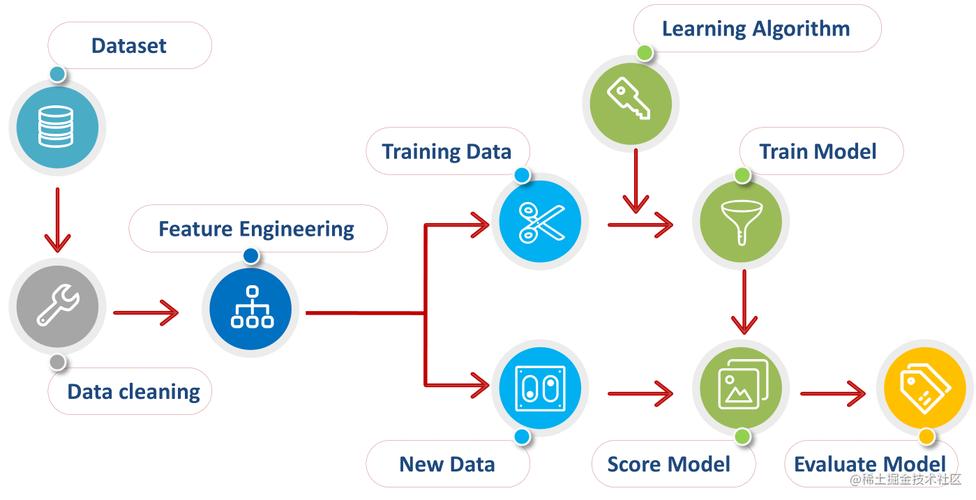
1、数据准备:需要收集和预处理数据,这通常包括数据清洗、缺失值处理、异常值检测和数据归一化等步骤。
2、特征选择:选择合适的特征对于模型的性能至关重要,可以使用相关性分析、主成分分析(PCA)等方法来选择最重要的特征。
3、模型选择:根据问题的类型(如分类、回归或聚类),选择合适的机器学习算法,MLS提供了多种算法,如决策树、随机森林、支持向量机(SVM)、神经网络等。
4、模型训练:使用训练数据集对选定的模型进行训练,这个过程通常涉及调整模型参数(称为超参数)以优化模型性能。
5、模型评估:使用验证数据集来评估模型的性能,常用的评估指标包括准确率、召回率、F1分数、均方误差(MSE)等。
6、模型优化:根据模型评估的结果,可能需要返回到前面的步骤进行调整,如改变特征选择、尝试不同的模型或调整超参数。
7、模型部署:一旦模型经过充分训练和验证,就可以将其部署到生产环境中,用于实际的数据预测或决策支持。
案例分析
假设我们要预测一个电商平台上的用户购买行为,我们可以使用MLS预置算链来构建一个分类模型,步骤如下:
数据准备:收集用户的浏览历史、购买历史、点击率等数据,并进行预处理。
特征选择:通过分析,我们选择了用户的浏览时长、点击次数、历史购买量等作为特征。
模型选择:我们选择了随机森林作为分类模型。
模型训练:使用80%的数据进行模型训练。
模型评估:使用剩余的20%数据进行模型评估,发现准确率达到了85%。
模型优化:通过调整随机森林的树的数量和深度,进一步提高了模型的准确性。
模型部署:将模型部署到线上系统,实时预测用户的购买概率,并据此推荐商品。
相关问答FAQs
Q1: MLS预置算链与传统机器学习流程有何不同?
A1: MLS预置算链提供了一套标准化的工作流程和丰富的预置算法库,使得用户可以更快速地搭建和测试机器学习模型,而不需要从头开始编写代码,它通过自动化许多常见的数据处理和模型训练任务,降低了机器学习的入门门槛。
Q2: 如何确保使用MLS预置算链得到的模型具有良好的泛化能力?
A2: 确保模型具有良好的泛化能力需要遵循一些最佳实践,例如使用交叉验证来评估模型性能,避免过拟合,以及在多个不同的数据集上测试模型,定期重新训练模型以适应新的数据模式也很重要。
通过上述步骤和注意事项,我们可以有效地使用MLS预置算链进行机器学习建模,解决各种复杂的数据分析问题。
原创文章,作者:未希,如若转载,请注明出处:https://www.kdun.com/ask/675510.html
本网站发布或转载的文章及图片均来自网络,其原创性以及文中表达的观点和判断不代表本网站。如有问题,请联系客服处理。
发表回复