


Parquet Format
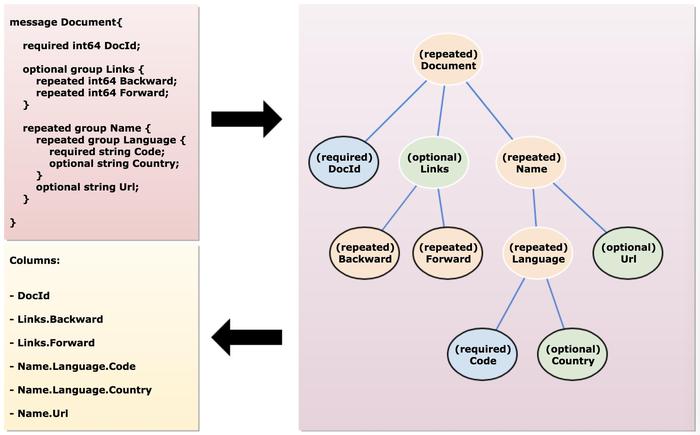

Parquet是一种列式存储的文件格式,用于高效地存储和处理大量数据,它是由Twitter和Cloudera共同开发,旨在提高大数据处理的性能,特别是在Hadoop生态系统中。
1. 设计目标
列式存储:与行式存储相比,列式存储允许更高效的数据压缩和查询性能。
嵌套数据结构:支持复杂的数据模型,如Protobuf和Avro。
可扩展性:设计上支持未来的编码和压缩算法。
2. 文件结构
Row Group:数据被分成多个Row Groups,每个Row Group包含多列数据。
Column Chunk:每列数据进一步被分割成多个Column Chunks,每个Chunk存储一列的部分数据。
Page:Column Chunk由多个Page组成,Page是最小的编码单位。
3. 编码和压缩
编码:Parquet支持多种编码方式,如字典编码、RLE编码等,以减少数据大小。
压缩:可以使用gzip、LZO等多种压缩算法来进一步减小文件大小。
4. 性能优势
快速查询:由于是列式存储,只读取需要的列,减少了I/O操作。
高效编码:有效的编码和压缩减少了磁盘空间和网络传输。
向量化查询执行:支持现代数据库和数据处理框架的向量化查询执行。
5. 适用场景
大数据分析:适用于需要处理大量数据的批处理和交互式查询。
数据仓库:适合作为数据仓库的存储格式,特别是OLAP场景。
机器学习:对于需要频繁扫描大量特征列的机器学习工作负载非常有用。
6. 兼容性
语言支持:支持多种编程语言,如Java、Python、R等。
生态系统:与Hadoop生态系统紧密集成,包括Hive、Spark、Presto等。
7. 社区和未来展望
开源项目:Parquet是一个开源项目,拥有活跃的社区支持。
持续发展:随着技术的发展,Parquet持续改进其性能和功能,适应新的数据处理需求。
8. 使用案例
企业分析:许多企业使用Parquet作为数据湖或数据仓库的存储格式,以支持复杂的分析查询。
云服务:云服务提供商如AWS、Azure和Google Cloud也提供对Parquet格式的支持。
Parquet格式因其高效的存储和快速查询能力,在大数据和分析领域得到了广泛的应用,它的设计充分考虑了现代数据处理的需求,使其成为处理大规模数据集的理想选择。
原创文章,作者:未希,如若转载,请注明出处:https://www.kdun.com/ask/672652.html
本网站发布或转载的文章及图片均来自网络,其原创性以及文中表达的观点和判断不代表本网站。如有问题,请联系客服处理。
发表回复