


PHP爬虫技术知识点归纳
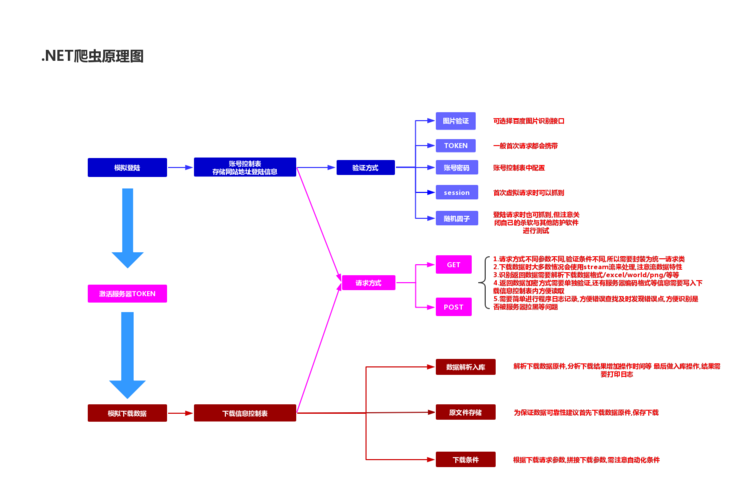

1. 概述
定义:PHP爬虫是一种使用PHP编程语言编写的,用于自动访问网页并提取信息的脚本或程序。
作用:主要用于数据采集、监控和分析。
2. 基础准备
环境搭建:安装PHP环境,配置相关依赖。
HTTP请求:了解如何使用PHP发送HTTP请求。
3. 常用库和工具
cURL:PHP自带的库,用于发送各种类型的HTTP请求。
Guzzle:一个PHP的HTTP客户端,支持异步请求。
Symfony HttpClient:Symfony框架提供的HTTP客户端。
4. 数据提取
DOM解析:使用PHP内置的DOM解析器来解析HTML文档。
正则表达式:使用正则表达式来匹配和提取数据。
XPath:使用XPath查询语言从XML或HTML文档中提取数据。
5. 数据存储
数据库:将数据存储到MySQL、PostgreSQL等数据库中。
文件:将数据保存到CSV、JSON、XML等格式的文件中。
6. 反爬虫策略
UserAgent:模拟不同的用户代理(UserAgent)来避免被识别为爬虫。
IP代理:使用IP代理来避免IP被封。
Cookies和Session:处理Cookies和Session以维持登录状态或绕过某些限制。
7. 性能优化
并发请求:使用多线程或异步IO来并发发送请求,提高爬取效率。
缓存:使用缓存来避免重复请求相同的数据。
8. 法律和伦理问题
合法性:确保爬取的数据是公开可获取的,不违反任何法律条款。
Robots协议:遵守网站的Robots排除协议。
频率控制:合理控制爬取频率,避免对目标网站造成过大压力。
9. 进阶主题
动态内容爬取:处理JavaScript生成的动态内容。
登录和保持会话:处理需要登录的网站,保持会话状态。
验证码处理:处理验证码或其他人机验证机制。
10. 实践案例
简单爬虫示例:编写一个简单的PHP爬虫来爬取特定网站的数据。
复杂项目:设计并实现一个复杂的爬虫项目,如社交媒体数据分析工具。
11. 调试和测试
错误处理:添加错误处理代码,确保爬虫稳定运行。
单元测试:编写单元测试来验证爬虫的正确性。
12. 安全考虑
输入验证:对用户输入进行验证,防止注入攻击。
输出编码:对输出进行编码,防止跨站脚本攻击(XSS)。
13. 维护和更新
代码重构:定期重构代码以提高可读性和可维护性。
适应变化:跟踪目标网站的变化,及时更新爬虫策略。
14. 社区和资源
论坛和社区:参与PHP爬虫相关的论坛和社区,交流经验。
学习资源:查找和学习相关的在线教程、书籍和课程。
15. 未来趋势
机器学习:使用机器学习技术来优化爬虫策略。
云计算:利用云计算资源来提高爬虫的扩展性和可靠性。
原创文章,作者:未希,如若转载,请注明出处:https://www.kdun.com/ask/672324.html
本网站发布或转载的文章及图片均来自网络,其原创性以及文中表达的观点和判断不代表本网站。如有问题,请联系客服处理。
发表回复