


在Python中爬取网站数据通常涉及到网络请求、HTML解析和数据提取等步骤,静态网站托管则是将一个已经开发好的静态网站部署到互联网上,供用户访问,Python的SDK(Software Development Kit)提供了一系列的库和工具,使得开发者可以更加方便地完成这些任务。

网络请求
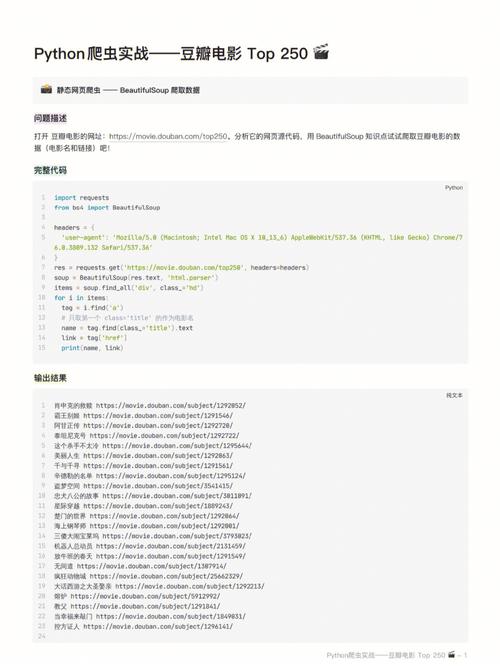
要爬取网站的数据,首先需要发起网络请求获取网页内容,Python中常用的库有requests和urllib。
requests库:这是一个非常流行的HTTP请求库,支持多种认证方式、会话机制、Cookie持久化等功能。
urllib库:这是Python内置的网络请求库,功能较为基础,但足以应对大多数情况。
HTML解析
获取到网页内容后,接下来需要解析HTML以提取所需数据,Python中常用的HTML解析库有BeautifulSoup和lxml。
BeautifulSoup库:这个库可以方便地从HTML或XML文件中提取数据,支持多种解析器(如lxml、html.parser等)。
lxml库:这是一个高性能的XML和HTML解析库,它提供了丰富的API来处理解析后的数据。
数据提取
解析完HTML之后,就可以根据需求提取所需的数据了,这通常涉及到遍历DOM树、查找特定标签和属性等操作。
使用BeautifulSoup或lxml库提供的API,可以轻松地定位到特定的HTML元素,并提取其文本内容、属性值等信息。
对于复杂的数据结构,可以使用Python的列表、字典等数据结构来存储和组织提取出的数据。
静态网站托管
静态网站托管是指将一个由纯HTML、CSS和JavaScript文件组成的网站部署到服务器上,供用户访问,Python的SDK提供了一些工具和库来简化这个过程。
Flask框架:虽然Flask主要用于构建Web应用,但它也可以用来托管静态网站,通过简单的配置,可以将静态文件暴露给外界访问。
WhiteNoise库:这个库可以与Flask配合使用,提供更好的静态文件服务支持,包括缓存控制、ETag支持等功能。
相关问答FAQs
Q1: Python中的网络请求库有哪些?
A1: Python中常用的网络请求库有requests和urllib。requests库提供了更高级的功能和更简洁的API,而urllib是Python内置的库,功能较为基础。
Q2: 如何选择合适的HTML解析库?
A2: 选择HTML解析库时,需要考虑解析速度、易用性和功能丰富程度等因素。BeautifulSoup库易于使用且功能强大,适合初学者;而lxml库则提供了更高的性能和更多的特性,适合对性能要求较高的场景。
原创文章,作者:未希,如若转载,请注明出处:https://www.kdun.com/ask/672049.html
本网站发布或转载的文章及图片均来自网络,其原创性以及文中表达的观点和判断不代表本网站。如有问题,请联系客服处理。
发表回复