


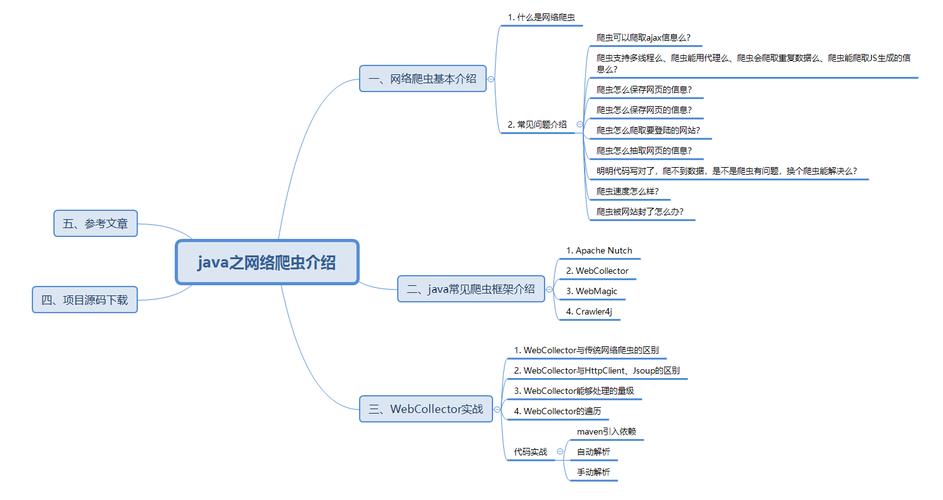
Java爬虫技术主要包括HttpClient、jsoup、WebMagic以及SpiderFlow等,具体如下:

(图片来源网络,侵删)
1、HttpClient: 是Apache提供的一个用于发送HTTP请求的库,它提供了丰富的API来发送HTTP请求和处理HTTP响应,HttpClient通常用于爬虫中的网络通信部分,负责与目标网站建立连接并获取网页内容。
2、jsoup: 是一个用于解析HTML文档的Java库,它提供了一个非常方便的API来提取和操作数据,使用DOM遍历或CSS选择器,Jsoup在Java爬虫中常用于解析HTML页面,提取所需的数据。
3、WebMagic: 是一款基于Java的分布式爬虫框架,使用了多线程和异步IO等技术,可以高效地爬取网站数据,WebMagic提供了丰富的插件机制,支持自定义解析器、处理器等功能。
4、SpiderFlow: 是一个轻量级的Java爬虫框架,它设计简单但功能强大,适合构建复杂的爬虫系统,SpiderFlow提供了灵活的数据流处理机制,可以方便地扩展和定制爬虫的行为。
除了上述技术外,还有其他一些技术和工具,如Nutch和Heritrix,它们也是Java开发的开源爬虫框架,主要用于大规模的网页抓取和索引。
这些框架和技术各有特点,适用于不同的场景和需求,在选择时,应根据项目的具体需求来决定使用哪种技术或框架。
原创文章,作者:未希,如若转载,请注明出处:https://www.kdun.com/ask/661504.html
本网站发布或转载的文章及图片均来自网络,其原创性以及文中表达的观点和判断不代表本网站。如有问题,请联系客服处理。
发表回复