


Docker搭建大数据集群

随着大数据技术的不断发展,越来越多的企业开始使用大数据技术来处理海量数据,Docker作为一种轻量级的容器技术,可以帮助我们快速搭建大数据集群,本文将介绍如何使用Docker搭建大数据集群。
1. Docker简介
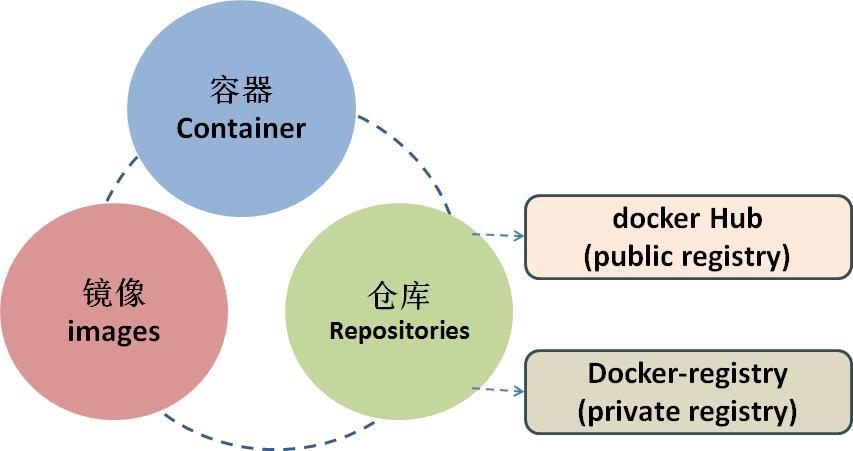
Docker是一个开源的应用容器引擎,它允许开发者将应用及其依赖打包到一个可移植的容器中,然后发布到任何流行的Linux机器或Windows机器上,也可以实现虚拟化,容器是完全使用沙箱机制,相互之间不会有任何接口。
2. Docker的优点
轻量级:相较于虚拟机,Docker容器更加轻量级,启动速度更快。
跨平台:Docker容器可以在任何支持Docker的平台上运行。
版本控制:Docker可以对容器进行版本控制,方便回滚和更新。
隔离性:Docker容器之间相互隔离,互不影响。
3. Docker搭建大数据集群的步骤
3.1 准备环境
首先需要安装Docker,可以参考Docker官方文档进行安装,安装完成后,需要确保所有的节点都已经安装了Docker。
3.2 选择镜像
在Docker Hub上有很多已经搭建好的大数据镜像,如Hadoop、Spark、Hive等,我们可以根据自己的需求选择合适的镜像,我们可以选择一个包含Hadoop、Spark、Hive的镜像。
3.3 创建容器
使用docker run命令创建容器,我们可以创建一个名为hadoopcluster的容器,并指定镜像名称为hadoopsparkhive:latest。
docker run d name hadoopcluster hadoopsparkhive:latest
3.4 配置集群
根据实际需求,我们需要对集群进行一些配置,如修改配置文件、设置环境变量等,这些操作可以通过进入容器内部进行。
docker exec it hadoopcluster /bin/bash
在容器内部,我们可以修改配置文件、设置环境变量等,完成配置后,需要重启相关服务使配置生效。
3.5 扩展集群
当需要扩展集群时,只需要重复上述步骤创建新的容器即可,Docker会自动管理容器之间的网络和存储。
4. 注意事项
确保所有节点的Docker版本一致,以免出现兼容性问题。
在配置集群时,需要注意各个组件之间的依赖关系,确保它们能够正常协同工作。
在扩展集群时,需要考虑负载均衡和数据备份等问题。
相关问答FAQs
Q1:Docker搭建大数据集群有哪些优点?
A1:Docker搭建大数据集群有以下几个优点:
1、轻量级:相较于虚拟机,Docker容器更加轻量级,启动速度更快。
2、跨平台:Docker容器可以在任何支持Docker的平台上运行。
3、版本控制:Docker可以对容器进行版本控制,方便回滚和更新。
4、隔离性:Docker容器之间相互隔离,互不影响。
Q2:如何扩展Docker搭建的大数据集群?
A2:扩展Docker搭建的大数据集群非常简单,只需要重复以下步骤:
1、准备环境:确保所有的节点都已经安装了Docker。
2、选择镜像:在Docker Hub上选择一个合适的大数据镜像。
3、创建容器:使用docker run命令创建一个新的容器。
4、配置集群:根据实际需求,对新创建的容器进行配置,这些操作可以通过进入容器内部进行,完成配置后,需要重启相关服务使配置生效。
原创文章,作者:未希,如若转载,请注明出处:https://www.kdun.com/ask/581103.html
本网站发布或转载的文章及图片均来自网络,其原创性以及文中表达的观点和判断不代表本网站。如有问题,请联系客服处理。
发表回复