


在使用 Flink CDC(Change Data Capture)的 Stream API 时,可以通过指定 tableList 来定义要捕获变更的表。tableList 是一个字符串列表,其中每个字符串表示一个表名,在指定 tableList 时,顺序并不重要,因为 Flink CDC 会并行地处理所有指定的表。
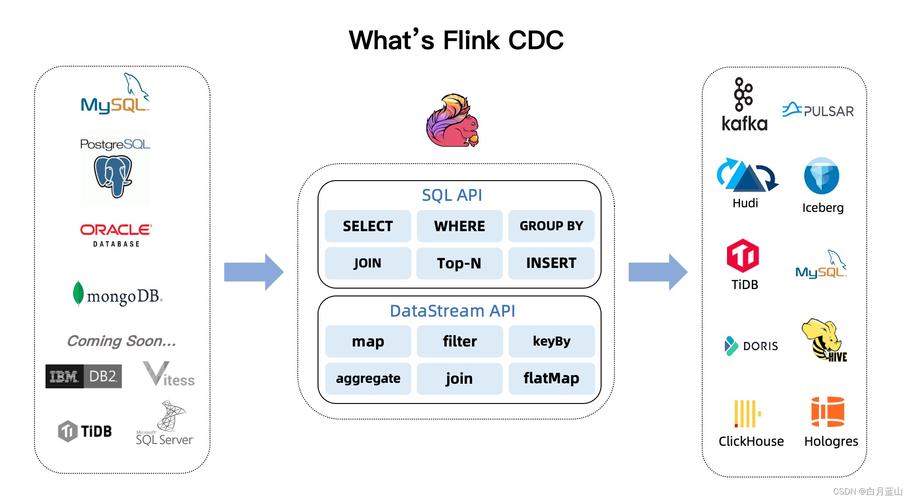

(图片来源网络,侵删)
以下是使用 Flink CDC Stream API 指定 tableList 的示例代码:
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.table.api.bridge.java.StreamTableEnvironment;
import org.apache.flink.table.api.bridge.java.internal.StreamTableEnvironmentImpl;
import org.apache.flink.table.api.EnvironmentSettings;
import org.apache.flink.table.catalog.hive.HiveCatalog;
import org.apache.flink.connector.jdbc.catalog.JdbcCatalog;
import org.apache.flink.connector.jdbc.catalog.JdbcCatalogFactoryOptions;
// 创建 Flink 流处理环境
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
EnvironmentSettings settings = EnvironmentSettings.newInstance().useBlinkPlanner().inStreamingMode().build();
StreamTableEnvironment tableEnv = StreamTableEnvironment.create(env, settings);
// 配置 Hive Catalog
String catalogName = "myhive";
String defaultDatabase = "mydatabase";
String hiveConfDir = "/path/to/hive/conf/directory";
HiveCatalog hiveCatalog = new HiveCatalog(catalogName, defaultDatabase, hiveConfDir);
// 注册 Hive Catalog
tableEnv.registerCatalog(catalogName, hiveCatalog);
tableEnv.useCatalog(catalogName);
// 设置 JdbcCatalog
String name = "mycatalog";
String defaultDatabase = "mydatabase";
String username = "username";
String password = "password";
String baseUrl = "jdbc:mysql://localhost:3306";
JdbcCatalog jdbcCatalog = new JdbcCatalog(name, defaultDatabase, username, password, baseUrl);
// 注册 JdbcCatalog
tableEnv.registerCatalog(name, jdbcCatalog);
tableEnv.useCatalog(name);
// 创建 source DDL
String sourceDDL = "CREATE TABLE my_source ( ... ) WITH ( ... )";
// 执行 source DDL
tableEnv.executeSql(sourceDDL);
// 创建 sink DDL
String sinkDDL = "CREATE TABLE my_sink ( ... ) WITH ( ... )";
// 执行 sink DDL
tableEnv.executeSql(sinkDDL);
// 定义 tableList
List<String> tableList = Arrays.asList("table1", "table2", "table3");
// 使用 Flink CDC Stream API 捕获表变更
DataStream<Row> cdcStream = tableEnv.toRetractStream(tableList, Row.class);
// 对 cdcStream 进行后续处理操作
cdcStream.map(...).returns(...).addSink(...);
// 启动 Flink 作业
env.execute("Flink CDC Stream Job");
在上述代码中,首先创建了 Flink 流处理环境和表环境,然后配置和注册了 Hive Catalog 和 JdbcCatalog,接下来,创建了源表和接收变更的汇聚表的 DDL,并执行了这些 DDL,通过调用 toRetractStream 方法,使用指定的 tableList 创建了一个捕获表变更的数据流 cdcStream,你可以对 cdcStream 进行后续的处理操作,例如映射、过滤等,启动 Flink 作业。
需要注意的是,以上代码仅为示例,实际情况下你需要根据你的环境和需求进行相应的配置和修改。
原创文章,作者:未希,如若转载,请注明出处:https://www.kdun.com/ask/558417.html
本网站发布或转载的文章及图片均来自网络,其原创性以及文中表达的观点和判断不代表本网站。如有问题,请联系客服处理。
发表回复