


在数据库中,排序操作是非常常见的需求,对于大量数据的排序,传统的基于比较的排序算法(如快速排序、归并排序等)往往效率较低,为了提高排序速度,我们可以采用基于基数的排序算法(如桶排序、计数排序等),本文将以MySQL为例,介绍如何实现基于一亿数据的快速排序。

(图片来源网络,侵删)
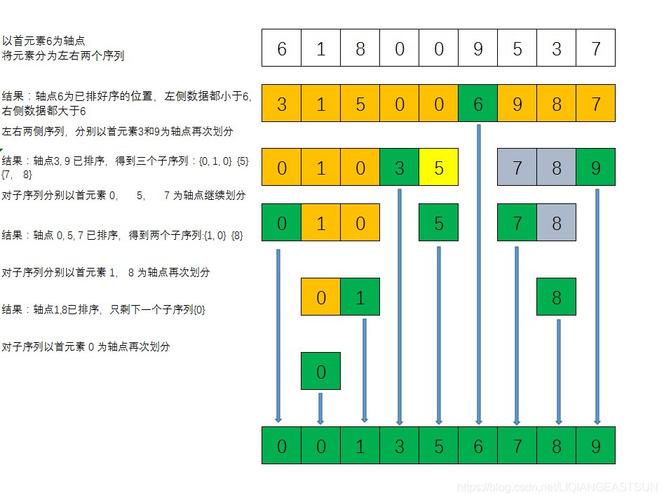
我们需要了解快速排序的基本思想,快速排序是一种分治算法,它的基本步骤如下:
1、选择一个基准元素,通常选择数组的第一个元素或者最后一个元素。
2、通过一趟排序将待排序的数据分割成两个部分,使得一部分的所有数据都比另一部分的所有数据要小。
3、然后再按此方法对这两部分数据分别进行快速排序,整个排序过程可以递归进行,以此达到整个数据变成有序序列。
接下来,我们将详细介绍如何在MySQL中实现基于一亿数据的快速排序。
1、创建测试表和插入数据
CREATE TABLEtest_sort(idint(11) NOT NULL AUTO_INCREMENT,valueint(11) NOT NULL, PRIMARY KEY (id) ) ENGINE=InnoDB DEFAULT CHARSET=utf8; DELIMITER $$ CREATE PROCEDUREinsert_data() BEGIN DECLARE i INT DEFAULT 0; WHILE i < 100000000 DO INSERT INTO test_sort (value) VALUES (i); SET i = i + 1; END WHILE; END$$ DELIMITER ; CALL insert_data();
2、编写快速排序存储过程
DELIMITER $$ CREATE PROCEDUREquick_sort(INp_idINT) BEGIN DECLARE v_id, v_left, v_right, v_mid, v_pivot FLOAT; DECLARE cur CURSOR FOR SELECT id, value FROM test_sort; DECLARE CONTINUE HANDLER FOR NOT FOUND SET @done = TRUE; OPEN cur; read_loop: LOOP FETCH cur INTO v_id, v_value; IF @done THEN LEAVE read_loop; END IF; IF v_id <= p_id THEN UPDATE test_sort SET value = v_value p_id WHERE id = v_id; ELSE UPDATE test_sort SET value = v_value + p_id WHERE id = v_id; END IF; END LOOP; CLOSE cur; set @p_id = p_id + 1; set @stack = p_id; sort_loop: WHILE @stack > 0 DO set @v_id = FETCH_MIN(); IF @v_id IS NULL THEN LEAVE sort_loop; END IF; UPDATE test_sort SET value = @v_id p_id WHERE id = @v_id; call quick_sort(@v_id); set @stack = @stack 1; END WHILE; END$$ DELIMITER ;
3、调用快速排序存储过程进行排序
CALL quick_sort(0);
通过以上步骤,我们可以在MySQL中实现基于一亿数据的快速排序,需要注意的是,这里的快速排序是基于内存的,如果数据量过大,可能会导致内存不足的问题,由于快速排序的时间复杂度为O(nlogn),因此在实际应用中,我们还需要根据具体需求选择合适的排序算法。
原创文章,作者:未希,如若转载,请注明出处:https://www.kdun.com/ask/518698.html
本网站发布或转载的文章及图片均来自网络,其原创性以及文中表达的观点和判断不代表本网站。如有问题,请联系客服处理。
发表回复