


在Python中,可以使用多种方法来缓存数据,以下是一些常见的方法:

(图片来源网络,侵删)
1、使用字典(Dictionary)作为缓存
字典是一种可变的、无序的、键值对集合,可以将需要缓存的数据存储在字典中,通过键来访问对应的值,这种方法简单易用,但需要注意线程安全问题。
示例代码:
创建一个字典作为缓存
cache = {}
def get_data(key):
# 如果缓存中有数据,直接返回
if key in cache:
return cache[key]
# 否则,获取数据并存入缓存
data = fetch_data(key) # fetch_data是一个获取数据的函数
cache[key] = data
return data
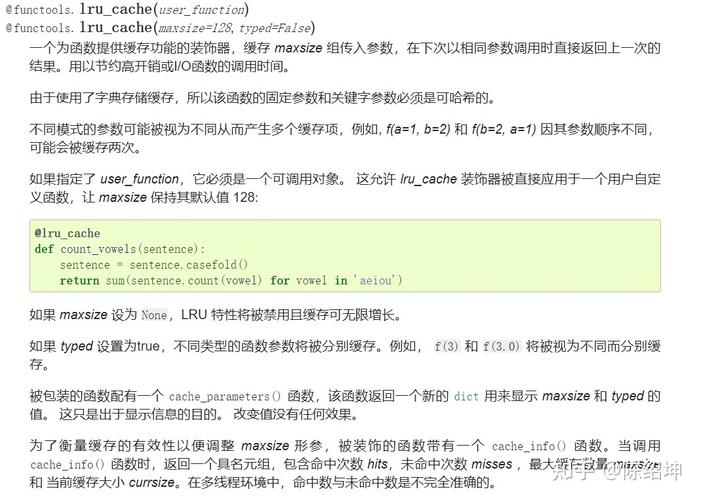
2、使用functools.lru_cache装饰器
functools.lru_cache是一个实现了LRU(Least Recently Used)算法的装饰器,可以自动为函数提供缓存功能,需要注意的是,functools.lru_cache只能用于无参数或单个参数的函数。
示例代码:
from functools import lru_cache
@lru_cache(maxsize=100) # 设置缓存大小为100
def get_data(key):
return fetch_data(key) # fetch_data是一个获取数据的函数
3、使用第三方库cachetools
cachetools是一个功能强大的缓存库,支持多种缓存策略,如LRU、LFU等,需要先安装cachetools库。
示例代码:
from cachetools import LRUCache, cached
cache = LRUCache(maxsize=100) # 设置缓存大小为100
@cached(cache)
def get_data(key):
return fetch_data(key) # fetch_data是一个获取数据的函数
4、使用文件系统作为缓存
将需要缓存的数据存储在文件中,通过文件名作为键来访问对应的数据,这种方法适用于数据量较小的情况。
示例代码:
import os
import pickle
def save_data(key, data):
with open(f"{key}.pkl", "wb") as f:
pickle.dump(data, f)
def load_data(key):
if os.path.exists(f"{key}.pkl"):
with open(f"{key}.pkl", "rb") as f:
return pickle.load(f)
return None
原创文章,作者:未希,如若转载,请注明出处:https://www.kdun.com/ask/471306.html
本网站发布或转载的文章及图片均来自网络,其原创性以及文中表达的观点和判断不代表本网站。如有问题,请联系客服处理。
发表回复