

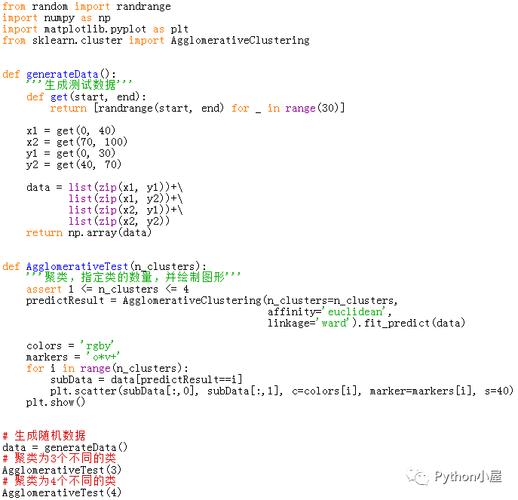
Python进行聚类的方法
在Python中,我们可以使用sklearn库中的KMeans算法进行聚类,以下是一个简单的示例:

(图片来源网络,侵删)
1、导入所需库
import numpy as np import matplotlib.pyplot as plt from sklearn.cluster import KMeans from sklearn.datasets import make_blobs
2、生成数据
随机生成数据 data, _ = make_blobs(n_samples=300, centers=4, cluster_std=0.6, random_state=0)
3、可视化数据
plt.scatter(data[:, 0], data[:, 1]) plt.show()
KMeans聚类算法
1、初始化参数
kmeans = KMeans(n_clusters=4, init='kmeans++', max_iter=300, n_init=10, random_state=0)
n_clusters表示聚类的数量,init表示初始化方法,max_iter表示最大迭代次数,n_init表示用不同的质心种子运行算法的次数,random_state表示随机数生成器的种子。
2、拟合数据
kmeans.fit(data)
3、预测结果
y_kmeans = kmeans.predict(data)
4、可视化结果
plt.scatter(data[:, 0], data[:, 1], c=y_kmeans, s=50, cmap='viridis') centers = kmeans.cluster_centers_ plt.scatter(centers[:, 0], centers[:, 1], c='black', s=200, alpha=0.5) plt.show()
归纳
通过以上步骤,我们可以使用Python的sklearn库进行聚类,在实际应用中,可以根据具体问题调整KMeans算法的参数以获得更好的聚类效果。
原创文章,作者:未希,如若转载,请注明出处:https://www.kdun.com/ask/467345.html
本网站发布或转载的文章及图片均来自网络,其原创性以及文中表达的观点和判断不代表本网站。如有问题,请联系客服处理。
发表回复