


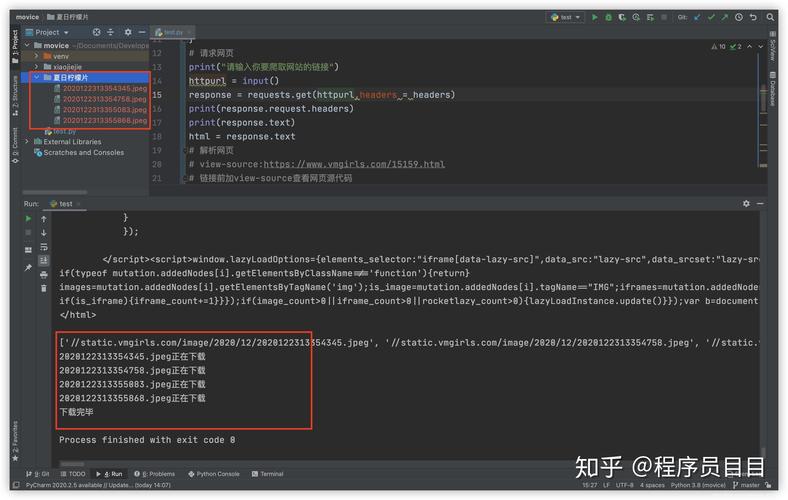
要用Python抓取网页图片,可以使用requests库来获取网页内容,然后使用BeautifulSoup库来解析HTML并提取图片链接,接下来,再次使用requests库下载图片,以下是详细的步骤和代码示例:

(图片来源网络,侵删)
1、安装所需库
确保已经安装了requests和beautifulsoup4库,如果没有安装,可以使用以下命令安装:
pip install requests beautifulsoup4
2、导入所需库
在Python脚本中,导入所需的库:
import requests from bs4 import BeautifulSoup import os
3、获取网页内容
使用requests.get()方法获取网页内容:
url = 'https://example.com' # 替换为你要抓取图片的网页链接 response = requests.get(url) html_content = response.text
4、解析HTML并提取图片链接
使用BeautifulSoup解析HTML内容,并提取图片链接:
soup = BeautifulSoup(html_content, 'html.parser')
img_tags = soup.find_all('img') # 查找所有的<img>标签
img_urls = [img['src'] for img in img_tags if 'src' in img.attrs] # 提取图片链接
5、下载图片
遍历图片链接列表,使用requests.get()方法下载图片,并将其保存到本地:
for img_url in img_urls:
img_data = requests.get(img_url).content
img_name = os.path.basename(img_url)
with open(img_name, 'wb') as f:
f.write(img_data)
将以上代码片段组合在一起,即可实现用Python抓取网页图片的功能。
原创文章,作者:未希,如若转载,请注明出处:https://www.kdun.com/ask/444282.html
本网站发布或转载的文章及图片均来自网络,其原创性以及文中表达的观点和判断不代表本网站。如有问题,请联系客服处理。
发表回复