

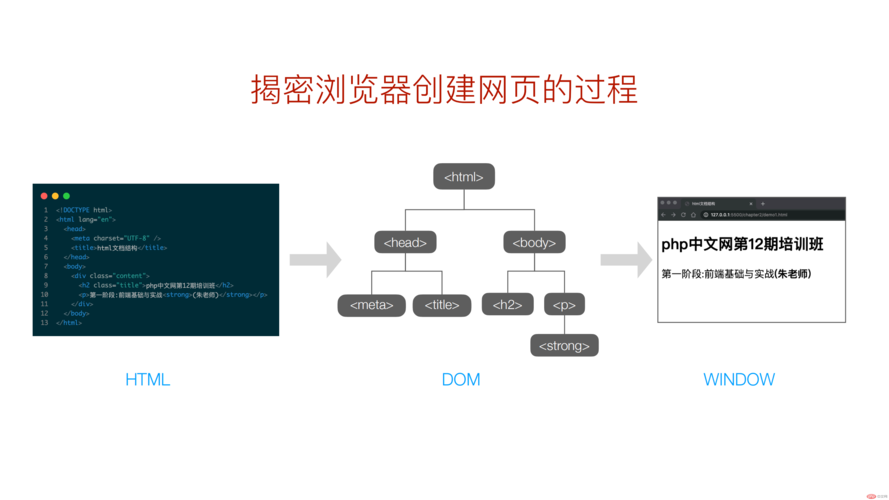
HTML(HyperText Markup Language,超文本标记语言)是用于创建网页的标准标记语言,它使用一系列标签来描述网页的内容和结构,解析HTML就是将HTML代码转换为浏览器可以理解和显示的网页内容的过程,在本文中,我们将详细介绍如何解析HTML。

1、学习HTML基础知识
要解析HTML,首先需要了解HTML的基本结构和标签,HTML文档由一系列的元素组成,这些元素被称为标签,标签通常成对出现,包括开始标签和结束标签。<p> 和 </p> 是一个段落的开始和结束标签,HTML文档还包含一些特殊标签,如 <!DOCTYPE>、<html>、<head> 和 <body> 等。
2、使用HTML解析器
HTML解析器是一种软件工具,用于将HTML代码转换为浏览器可以理解和显示的网页内容,有许多现成的HTML解析器可以使用,如Python的BeautifulSoup库、Java的Jsoup库等,这些库提供了丰富的API,可以方便地处理HTML文档的各个部分。
以Python的BeautifulSoup库为例,首先需要安装BeautifulSoup库:
pip install beautifulsoup4
可以使用以下代码解析HTML:
from bs4 import BeautifulSoup
html_doc = """
<!DOCTYPE html>
<html>
<head>
<title>示例网页</title>
</head>
<body>
<h1>欢迎来到示例网页</h1>
<p>这是一个用于演示如何解析HTML的简单网页。</p>
<ul>
<li>列表项1</li>
<li>列表项2</li>
<li>列表项3</li>
</ul>
</body>
</html>
"""
soup = BeautifulSoup(html_doc, 'html.parser')
print(soup.prettify())
3、提取HTML元素信息
解析HTML后,可以使用BeautifulSoup库提供的方法提取HTML元素的信息,以下是一些常用的方法:
tag:获取元素的标签名。
name:获取元素的标签名(不区分大小写)。
text:获取元素的文本内容。
get_text():获取元素的文本内容,同时去除多余的空白字符。
find():查找符合条件的第一个元素。
find_all():查找符合条件的所有元素。
parent:获取元素的父元素。
children:获取元素的所有子元素。
next_sibling:获取元素的下一个兄弟元素。
previous_sibling:获取元素的上一个兄弟元素。
attrs:获取元素的所有属性。
get(attr_name):获取指定属性的值。
has_attr(attr_name):判断元素是否具有指定属性。
replace_with():替换元素及其子元素的内容。
append():在元素的末尾添加新的内容。
insert():在指定位置插入新的内容。
remove():删除元素及其子元素的内容。
clear():清除元素的所有内容。
decompose():删除元素及其子元素的内容,并释放内存。
4、遍历HTML文档树
BeautifulSoup库提供了一个名为descendants的属性,可以用于遍历HTML文档树,以下是一个遍历HTML文档树的示例:
for tag in soup.descendants:
print(tag.name)
5、保存解析后的HTML内容
解析HTML后,可以将结果保存到文件中,以下是一个将解析后的HTML内容保存到文件的示例:
with open('output.html', 'w', encoding='utf8') as f:
f.write(str(soup))
通过学习HTML基础知识、使用HTML解析器、提取HTML元素信息、遍历HTML文档树以及保存解析后的HTML内容,我们可以掌握如何解析HTML,在实际开发中,可以根据需求选择合适的HTML解析器和相关技术,以便更高效地处理HTML文档。
原创文章,作者:未希,如若转载,请注明出处:https://www.kdun.com/ask/434988.html
本网站发布或转载的文章及图片均来自网络,其原创性以及文中表达的观点和判断不代表本网站。如有问题,请联系客服处理。
发表回复