


Spark Streaming 是 Apache Spark 核心API的扩展之一,它支持高吞吐量、容错能力强且能够与外部系统进行实时集成的实时数据处理,以下是关于Spark Streaming特性的详细介绍和如何使用它的技术教学。
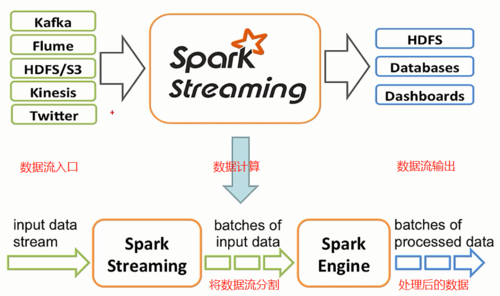

Spark Streaming的核心特性
1、高吞吐量:Spark Streaming 能够处理大量实时数据流,并且能够以高吞吐量进行处理。
2、容错性:通过使用微批处理方法(microbatch processing),Spark Streaming 可以提供良好的容错性能。
3、易于使用:Spark Streaming 提供了简单的API来操作数据流,并且可以利用Spark生态系统中的其他组件。
4、实时处理:虽然有微小的处理延迟,但Spark Streaming 能够近乎实时地处理数据。
5、可扩展性:可以轻松地在多个节点上扩展,以处理更大数据量。
6、多种数据源支持:可以从Kafka、Flume、Kinesis或TCP套接字等来源接收实时数据。
7、丰富的操作:支持各种转换操作,如map、reduce、join和window等。
8、与Spark生态系统集成:可以使用MLlib、GraphX等其他Spark组件进行机器学习、图计算等高级分析。
9、持久化机制:可以将数据保存到文件系统,数据库或其他存储系统中。
技术教学:如何使用Spark Streaming
环境准备
确保你已经安装了Apache Spark及其Streaming模块,你还需要安装Java和Scala(Spark支持的语言)以及相关的构建工具如Maven或sbt。
创建一个简单的Spark Streaming应用
1、导入依赖:
在你的项目中,添加以下依赖(假设使用Scala编写):
“`scala
libraryDependencies += "org.apache.spark" %% "sparkstreaming" % "x.y.z" // 使用你的Spark版本号
“`
2、初始化SparkConf和StreamingContext:
“`scala
import org.apache.spark.SparkConf
import org.apache.spark.streaming.StreamingContext
val conf = new SparkConf().setAppName("MyStreamingApp").setMaster("local[*]")
val ssc = new StreamingContext(conf, Seconds(1)) // 设置批处理间隔为1秒
“`
3、从数据源读取数据:
假设我们从Kafka中读取数据:
“`scala
import org.apache.spark.streaming.kafka010._
val kafkaParams = Map[String, Object](
"bootstrap.servers" > "localhost:9092",
"key.deserializer" > classOf[StringDeserializer],
"value.deserializer" > classOf[StringDeserializer],
"group.id" > "example",
"auto.offset.reset" > "latest",
"enable.auto.commit" > (false: java.lang.Boolean)
)
val topics = Array("mytopic")
val stream = KafkaUtils.createDirectStream[String, String](
ssc,
PreferConsistent,
Subscribe[String, String](topics, kafkaParams)
)
“`
4、处理数据流:
定义一个处理逻辑,例如对数据进行单词计数:
“`scala
val words = stream.flatMap(record => record.value().split(" "))
val wordCounts = words.countByValue()
“`
5、输出结果:
将结果输出到控制台或者其他存储系统:
“`scala
wordCounts.print()
“`
6、启动和等待:
开始流处理并等待其完成:
“`scala
ssc.start()
ssc.awaitTermination()
“`
这样,我们就创建了一个简单的Spark Streaming应用程序,它从Kafka中读取数据,执行单词计数,并将结果打印出来。
优化和部署
性能调优:可以通过调整Spark配置参数来优化性能,比如增加executor数量、内存分配等。
部署模式:可以选择本地模式进行开发测试,在生产环境中通常需要部署到集群中。
监控和日志:利用Spark提供的监控界面跟踪应用程序的状态,并通过日志收集系统记录程序运行日志。
结论
Spark Streaming是一个强大的实时数据处理框架,它提供了高吞吐量、容错能力及与外部系统实时集成的能力,通过上述的技术教学,你应该能够理解其基本概念并学会如何创建、配置和优化一个Spark Streaming应用程序,随着实践的深入,你将能够掌握更多高级功能,以满足复杂的实时数据处理需求。
原创文章,作者:酷盾叔,如若转载,请注明出处:https://www.kdun.com/ask/308841.html
本网站发布或转载的文章及图片均来自网络,其原创性以及文中表达的观点和判断不代表本网站。如有问题,请联系客服处理。
发表回复