


在Python中,函数是一段可重用的代码,用于执行特定任务,函数可以接受输入参数并返回结果,使用函数可以使代码更简洁、易读和易于维护,本文将详细介绍如何在Python中使用函数,以及如何从互联网获取最新内容。
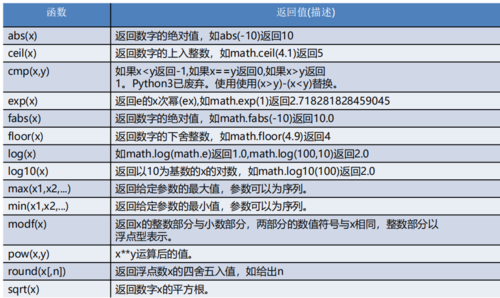

1、定义函数
要定义一个函数,需要使用def关键字,后跟函数名和括号内的参数列表,函数体以冒号开始,后面的代码块需要缩进。
def function_name(parameter1, parameter2):
# 函数体
return result
定义一个简单的加法函数:
def add(a, b):
result = a + b
return result
2、调用函数
要调用函数,只需使用函数名和括号内的参数列表,调用上面定义的add函数:
sum = add(3, 5) print(sum) # 输出:8
3、从互联网获取最新内容
要从互联网获取最新内容,可以使用Python的requests库,需要安装requests库:
pip install requests
接下来,使用requests.get()方法获取网页内容,获取GitHub首页的HTML内容:
import requests url = 'https://github.com' response = requests.get(url) html_content = response.text print(html_content)
4、解析HTML内容
要从HTML内容中提取信息,可以使用Python的BeautifulSoup库,需要安装beautifulsoup4库:
pip install beautifulsoup4
接下来,使用BeautifulSoup解析HTML内容,并提取所需信息,提取GitHub首页的所有仓库名称:
from bs4 import BeautifulSoup
soup = BeautifulSoup(html_content, 'html.parser')
repos = soup.find_all('a', class_='valignmiddle')
for repo in repos:
print(repo.text)
5、定时获取最新内容
要定时获取最新内容,可以使用Python的schedule库,需要安装schedule库:
pip install schedule
接下来,使用schedule.every()方法设置定时任务,并使用schedule.run_pending()方法运行待处理的任务,每隔1小时获取一次GitHub首页的仓库名称:
import schedule
import time
def get_repos():
# 获取GitHub首页的HTML内容
# 解析HTML内容并提取仓库名称
pass
每隔1小时执行一次get_repos函数
schedule.every(1).hours.do(get_repos)
while True:
schedule.run_pending()
time.sleep(1)
本文详细介绍了如何在Python中使用函数,以及如何从互联网获取最新内容,通过使用requests库获取网页内容,使用BeautifulSoup库解析HTML内容,以及使用schedule库定时执行任务,可以轻松实现从互联网获取最新内容的功能。
原创文章,作者:酷盾叔,如若转载,请注明出处:https://www.kdun.com/ask/305799.html
本网站发布或转载的文章及图片均来自网络,其原创性以及文中表达的观点和判断不代表本网站。如有问题,请联系客服处理。
发表回复