


在Python中,我们通常使用正则表达式(Regular Expression)来匹配字符串,正则表达式是一种强大的文本处理工具,它提供了一种灵活的方式来搜索或匹配特定的字符串模式。
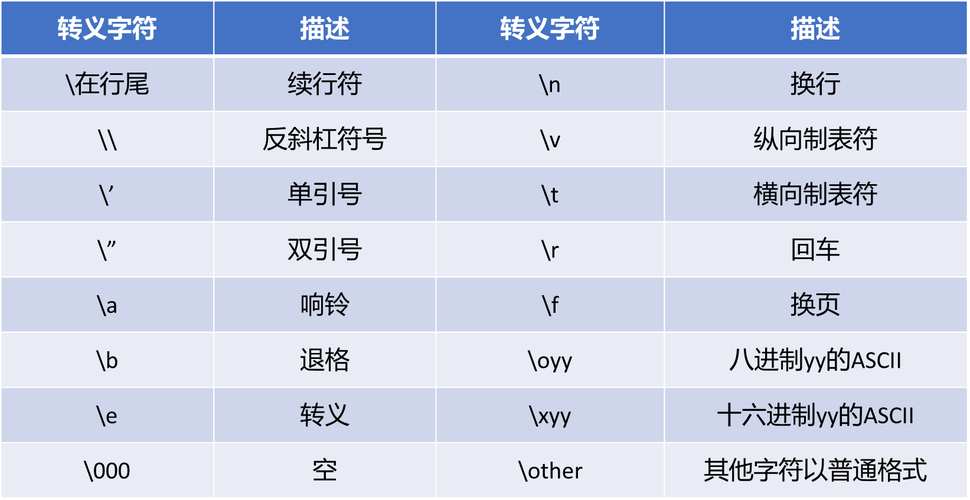

以下是一些基本的Python正则表达式操作:
1、re.match():从字符串的起始位置匹配一个模式,如果不是起始位置匹配成功的话,返回none。
2、re.search():扫描整个字符串并返回第一个成功的匹配。
3、re.findall():返回一个列表,其中包含字符串中所有与模式匹配的所有子串。
4、re.finditer():返回一个迭代器,其中包含字符串中所有与模式匹配的所有非重复子串。
5、re.sub():替换字符串中的匹配项。
接下来,我们将通过一些示例来详细解释这些操作。
我们需要导入Python的正则表达式模块:
import re
1、re.match()函数
result = re.match(r'abc', 'abcdef') print(result) # <re.Match object; span=(0, 3), match='abc'>
在这个例子中,我们在字符串’abcdef’的开始位置匹配模式’abc’,如果匹配成功,re.match()函数将返回一个匹配对象,否则返回None。
2、re.search()函数
result = re.search(r'abc', 'abcdefabc') print(result) # <re.Match object; span=(0, 3), match='abc'>
在这个例子中,我们在字符串’abcdefabc’中搜索模式’abc’,如果找到匹配,re.search()函数将返回一个匹配对象,否则返回None。
3、re.findall()函数
result = re.findall(r'abc', 'abcdefabc') print(result) # ['abc', 'abc']
在这个例子中,我们在字符串’abcdefabc’中找到所有的’abc’。re.findall()函数将返回一个包含所有匹配的列表。
4、re.finditer()函数
result = re.finditer(r'abc', 'abcdefabc')
for match in result:
print(match)
在这个例子中,我们在字符串’abcdefabc’中找到所有的’abc’。re.finditer()函数将返回一个迭代器,其中包含所有匹配的对象。
5、re.sub()函数
result = re.sub(r'abc', 'def', 'abcdefabc') print(result) # 'defdefdef'
在这个例子中,我们在字符串’abcdefabc’中将所有的’abc’替换为’def’。re.sub()函数将返回一个新的字符串,其中所有的匹配都被替换。
以上就是Python中正则表达式的基本操作,在实际使用中,我们还可以使用更复杂的模式来进行匹配和替换,例如使用通配符、限定符等。
原创文章,作者:酷盾叔,如若转载,请注明出处:https://www.kdun.com/ask/305005.html
本网站发布或转载的文章及图片均来自网络,其原创性以及文中表达的观点和判断不代表本网站。如有问题,请联系客服处理。
发表回复