


在Java中,Jsoup是一个非常流行的HTML解析库,它可以用来从网页上抓取数据,如果你想要使用Jsoup来解析HTML并提取链接里面的内容,可以按照以下步骤进行操作:
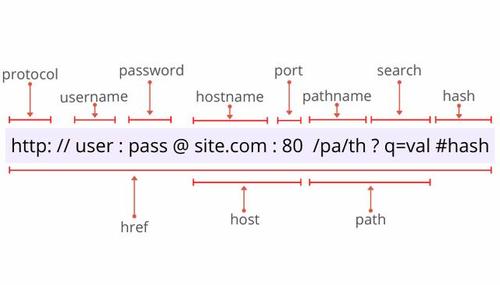

1、引入Jsoup库:
确保你的项目中已经添加了Jsoup的依赖,如果你使用的是Maven项目,可以在pom.xml文件中添加以下依赖:
“`xml
<dependencies>
<dependency>
<groupId>org.jsoup</groupId>
<artifactId>jsoup</artifactId>
<version>1.14.3</version> <!请检查最新版本 >
</dependency>
</dependencies>
“`
2、获取HTML内容:
使用Jsoup连接到指定的URL并获取HTML内容,以下是一个简单的示例:
“`java
import org.jsoup.Jsoup;
import org.jsoup.nodes.Document;
public class JsoupExample {
public static void main(String[] args) {
try {
// 连接到指定URL并获取HTML文档
Document document = Jsoup.connect("https://example.com").get();
// 打印整个HTML文档
System.out.println(document.html());
} catch (IOException e) {
e.printStackTrace();
}
}
}
“`
3、解析HTML并提取链接:
使用Jsoup的选择器语法来提取HTML中的链接,以下是提取所有<a>标签中的链接的示例:
“`java
import org.jsoup.Jsoup;
import org.jsoup.nodes.Document;
import org.jsoup.nodes.Element;
import org.jsoup.select.Elements;
public class JsoupExample {
public static void main(String[] args) {
try {
// 连接到指定URL并获取HTML文档
Document document = Jsoup.connect("https://example.com").get();
// 提取所有<a>标签中的链接
Elements links = document.select("a[href]");
// 遍历链接并打印
for (Element link : links) {
System.out.println("链接文本: " + link.text());
System.out.println("链接地址: " + link.attr("abs:href"));
}
} catch (IOException e) {
e.printStackTrace();
}
}
}
“`
在上面的代码中,我们使用了a[href]选择器来匹配所有包含href属性的<a>标签,我们遍历每个链接元素,并打印出链接的文本和绝对URL。
4、进一步处理链接内容:
一旦你提取了链接,你可以根据需要进一步处理它们,你可以打开每个链接并获取其HTML内容,然后解析该内容以提取你需要的数据,以下是一个示例,展示如何打开每个链接并打印其标题(如果存在):
“`java
import org.jsoup.Jsoup;
import org.jsoup.nodes.Document;
import org.jsoup.nodes.Element;
import org.jsoup.select.Elements;
public class JsoupExample {
public static void main(String[] args) {
try {
// 连接到指定URL并获取HTML文档
Document document = Jsoup.connect("https://example.com").get();
// 提取所有<a>标签中的链接
Elements links = document.select("a[href]");
// 遍历链接并处理每个链接的内容
for (Element link : links) {
String url = link.attr("abs:href");
// 连接到链接的URL并获取HTML文档
Document linkDocument = Jsoup.connect(url).get();
// 提取标题(如果存在)
String title = linkDocument.title();
// 打印链接地址和标题
System.out.println("链接地址: " + url);
System.out.println("标题: " + title);
}
} catch (IOException e) {
e.printStackTrace();
}
}
}
“`
在上面的代码中,我们首先提取了所有链接,然后对于每个链接,我们连接到它的URL并获取其HTML内容,接下来,我们提取了该链接的标题(如果存在),并打印出链接地址和标题。
这些是使用Jsoup解析HTML并提取链接内容的基本步骤,你可以根据具体需求进一步扩展和定制你的代码,以满足你的数据抓取要求。
原创文章,作者:酷盾叔,如若转载,请注明出处:https://www.kdun.com/ask/303224.html
本网站发布或转载的文章及图片均来自网络,其原创性以及文中表达的观点和判断不代表本网站。如有问题,请联系客服处理。
发表回复