

面向大数据的开源推荐系统分析

在大数据时代,信息过载问题愈发严重,如何从海量数据中提取有价值的信息成为了一个关键挑战,推荐系统作为解决这一问题的有效工具,得到了广泛应用和研究,本文将重点讨论面向大数据的开源推荐系统,分析其技术特点和应用现状,并探讨如何应对大数据时代的挑战。
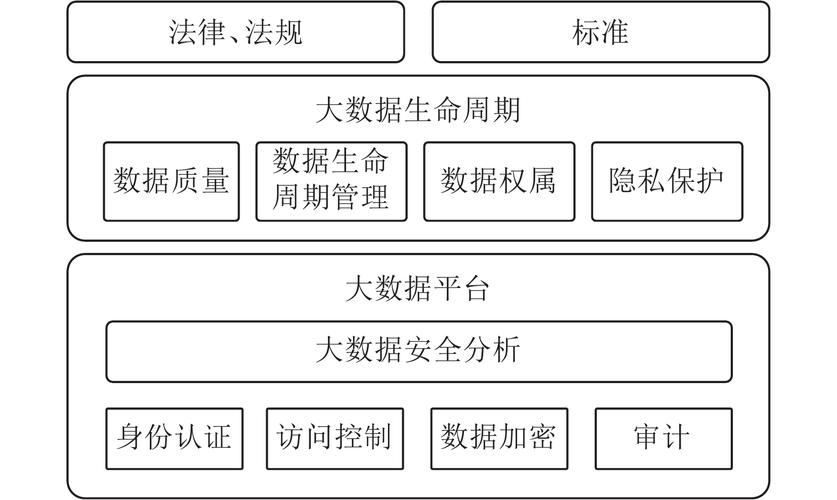
大数据的定义与特征
大数据通常被定义为符合“4V”标准的数据:大容量(Volume)、高速度(Velocity)、多样性(Variety)和真实性(Veracity),这些特征使得传统的数据处理方法难以应对,需要新的技术和工具来处理和分析。
| 大数据特征 | 描述 |
| 大容量(Volume) | 数据量巨大,从TB到PB级别 |
| 高速度(Velocity) | 数据生成和处理速度快 |
| 多样性(Variety) | 数据类型多样,包括结构化和非结构化数据 |
| 真实性(Veracity) | 数据的质量和可信度参差不齐 |
推荐系统的基本原理
推荐系统通过分析用户行为和偏好,为用户提供个性化的推荐,其主要任务是预测用户对某一项目的兴趣,常见的推荐算法包括协同过滤、基于内容的推荐和混合推荐等。
开源推荐系统概述
开源推荐系统是指那些开放源代码的推荐系统项目,它们具有高度的灵活性和可扩展性,广泛应用于各种领域,以下是几种常见的开源推荐系统:
1、Apache Mahout:基于Hadoop的机器学习和数据挖掘库,支持多种推荐算法。
2、LensKit:用于研究和实验的推荐系统框架,提供丰富的算法和工具。
3、Surprise:Python库,用于构建和分析推荐系统,支持矩阵分解等算法。
开源推荐系统的优势与挑战
5.1 优势
1、灵活性:开源系统可以根据具体需求进行定制和优化。

2、社区支持:拥有活跃的开源社区,可以获取技术支持和更新。
3、成本效益:免费使用,降低了开发和维护成本。
5.2 挑战
1、性能问题:面对海量数据,传统单机环境的性能受限。
2、扩展性:系统需要具备良好的扩展性以应对不断增长的数据量。
3、实时性:如何在保证实时性的前提下提供高质量的推荐。
案例分析:基于Hadoop的电影推荐系统
论文《基于大数据分析的推荐系统研究》提出了一种基于分布式开源框架Hadoop的电影推荐系统,该系统利用Hadoop的HDFS和MapReduce进行大规模数据处理和计算,采用改进的基于项目的协同过滤算法(IBCF),实现了高效的电影推荐。
| 功能项 | Hadoop版电影推荐系统 | 传统单机环境 |
| 数据处理能力 | 高效处理PB级数据 | 受限于单机性能 |
| 扩展性 | 良好 | 有限 |
| 实时性 | 较好 | 较差 |
常见问题解答
1、Q1: 如何选择适合的开源推荐系统?
A1: 选择时应考虑系统的性能、扩展性和社区支持情况,根据具体业务需求进行评估。

2、Q2: 如何处理推荐系统中的冷启动问题?
A2: 可以通过引入热门推荐、基于内容的推荐或利用社交网络数据来解决冷启动问题。
3、Q3: 如何提高推荐系统的准确性?
A3: 可以通过优化推荐算法、增加用户行为数据的丰富度和提高数据质量来提升准确性。
面向大数据的开源推荐系统在解决信息过载问题中发挥着重要作用,通过合理选择和优化开源推荐系统,企业可以有效应对大数据时代的挑战,为用户提供更加精准和个性化的推荐服务。
| 面向的读者 | 详细描述 |
| 数据分析师 | 对大数据分析有基本了解,希望深入了解推荐系统在数据挖掘中的应用和数据处理的细节。 |
| 推荐系统工程师 | 正在从事或对推荐系统开发感兴趣,需要学习如何构建、优化和维护推荐系统。 |
| 大数据开发人员 | 想要学习如何在他们的大数据项目中集成推荐系统,了解推荐系统的基础架构和实现方法。 |
| 算法研究人员 | 对推荐系统算法感兴趣,希望探索新的算法和模型,以及它们在大数据环境下的表现。 |
| 业务分析师 | 想要了解推荐系统如何帮助提升业务性能,特别是电商、社交媒体和在线内容平台等领域的应用。 |
| 研究生和本科生 | 正在攻读计算机科学、数据科学或相关领域学位的学生,希望学习推荐系统的理论和实践。 |
| 技术经理 | 负责技术团队的管理,需要理解推荐系统的技术挑战和商业价值,以指导团队进行技术决策。 |
| 产品经理 | 关注产品如何通过推荐系统提高用户体验和业务指标,希望了解推荐系统的设计原则和实施细节。 |
| 创业者和企业主 | 希望通过了解推荐系统来开拓新的业务模式,提升产品竞争力,并实现商业目标。 |
原创文章,作者:未希,如若转载,请注明出处:https://www.kdun.com/ask/1184316.html
本网站发布或转载的文章及图片均来自网络,其原创性以及文中表达的观点和判断不代表本网站。如有问题,请联系客服处理。


发表回复