

本地输入在MapReduce中的应用与实践

概述
MapReduce是一种编程模型,主要用于处理和生成大数据集,它最初由Google提出,并在Hadoop项目中得到了广泛应用,MapReduce的核心思想是将任务分解为多个小任务(称为“map”任务),然后对这些任务的结果进行汇总(称为“reduce”任务),这种模型非常适合于分布式计算环境,因为它可以有效地利用集群中的资源来并行处理数据。
在MapReduce作业中,输入数据通常来自分布式文件系统(如HDFS)或本地文件系统,本文将重点讨论如何使用本地文件作为MapReduce作业的输入,以及如何配置和优化这些作业以提高效率。
MapReduce作业的组成
在深入探讨之前,我们先简要回顾一下MapReduce作业的基本组成部分:
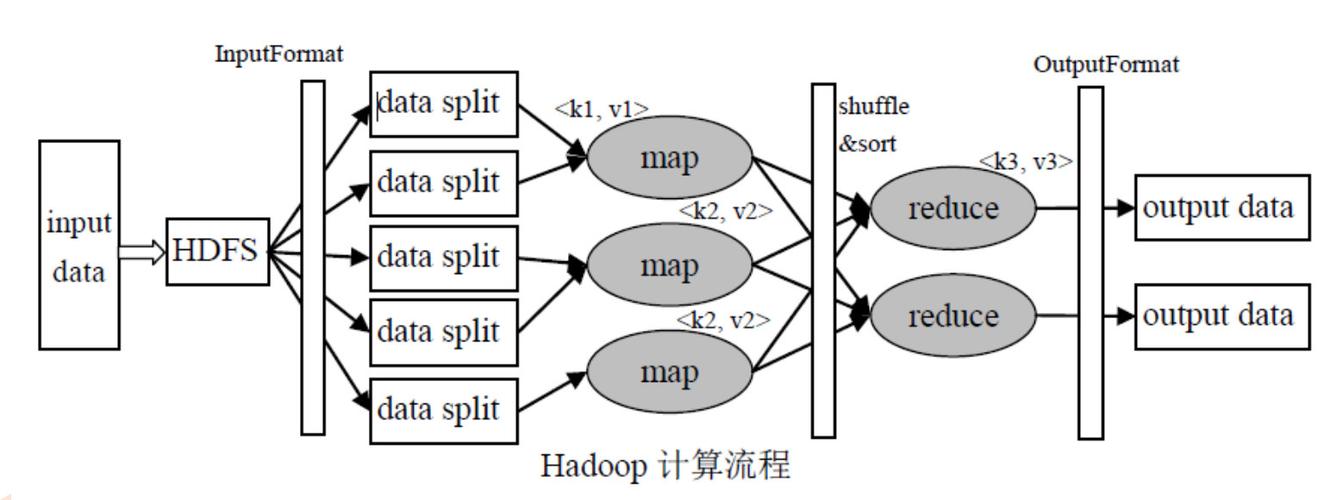
Mapper: 这是作业的第一个阶段,负责处理输入数据的单个记录,并将其转换为键值对。
Shuffle and Sort: 这个阶段发生在Map和Reduce之间,负责将Mapper的输出按键进行排序和分组,以便Reducer可以处理。
Reducer: 这是作业的最后阶段,负责接收相同键的所有值,并对它们进行处理以生成最终结果。
使用本地文件作为输入
当处理的数据量不大,或者需要快速原型开发时,使用本地文件作为MapReduce作业的输入是一个不错的选择,以下是如何在Hadoop中配置和使用本地文件的方法:
配置步骤
1、准备本地文件: 确保你的本地文件格式符合MapReduce作业的需求,如果是文本文件,确保每行都是一个独立的记录。

2、编写MapReduce程序: 使用Hadoop提供的API编写MapReduce程序,在程序中,你需要指定输入和输出格式,以及Mapper和Reducer的逻辑。
3、配置作业: 在你的MapReduce程序中,通过Job类的实例来配置作业,特别是,你需要设置以下参数:
setInputFormatClass: 指定输入格式,对于本地文件通常是TextInputFormat。
setOutputFormatClass: 指定输出格式,通常是TextOutputFormat。
setInputPath: 设置输入路径,这应该是一个指向本地文件系统的路径。
setOutputPath: 设置输出路径,这通常是HDFS上的路径。
4、运行作业: 编译并运行你的MapReduce程序,由于我们使用的是本地文件作为输入,你可能需要确保所有节点都能够访问这些文件,或者在一个单节点集群上运行作业。
示例代码
以下是一个简单的Java代码示例,展示了如何配置一个使用本地文件作为输入的MapReduce作业:
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
public class LocalInputExample {
public static void main(String[] args) throws Exception {
Configuration conf = new Configuration();
Job job = Job.getInstance(conf, "local input example");
job.setJarByClass(LocalInputExample.class);
job.setMapperClass(TokenizerMapper.class);
job.setCombinerClass(IntSumReducer.class);
job.setReducerClass(IntSumReducer.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
FileInputFormat.addInputPath(job, new Path(args[0]));
FileOutputFormat.setOutputPath(job, new Path(args[1]));
System.exit(job.waitForCompletion(true) ? 0 : 1);
}
} 在这个例子中,args[0]是指向本地文件系统的路径,而args[1]是HDFS上的输出路径。
性能优化
使用本地文件作为输入时,你可能会遇到性能瓶颈,因为读取本地文件系统的速度可能远低于HDFS,为了提高性能,你可以考虑以下优化策略:

压缩输入数据: 如果输入数据可以被压缩,那么在传输到各个节点之前先进行压缩可以节省网络带宽。
调整缓冲区大小: 增加Map任务的缓冲区大小可以减少磁盘I/O操作的次数,从而提高性能。
使用更快的本地存储介质: 如果可能的话,使用SSD代替HDD可以提高I/O速度。
FAQs
Q1: 是否可以在多节点集群上使用本地文件作为MapReduce的输入?
A1: 技术上是可行的,但并不推荐,因为如果每个节点都需要访问相同的本地文件,这可能会导致网络拥塞和性能下降,最佳做法是将输入数据上传到HDFS,然后让每个节点从HDFS读取数据。
Q2: 使用本地文件作为输入是否会影响MapReduce作业的容错性?
A2: 是的,使用本地文件可能会降低作业的容错性,如果在作业执行过程中某个节点发生故障,那么在该节点上未完成的任务可能需要重新分配到其他节点执行,如果这些任务依赖于特定的本地文件,那么就可能出现问题,使用HDFS作为输入可以提高作业的容错性和可靠性。
| 字段 | 描述 | 示例 |
| 文件路径 | 指定MapReduce作业中输入数据的文件路径 | hdfs://namenode:8020/input/data.txt |
| 文件名 | 输入数据的文件名 | data.txt |
| 数据格式 | 输入数据的格式,如文本、CSV、JSON等 | 文本 |
| 输入记录分隔符 | 用于分割输入数据记录的分隔符 | 换行符 |
| 输出键类型 | MapReduce作业输出键的数据类型 | String |
| 输出值类型 | MapReduce作业输出值的数据类型 | IntWritable |
| 输入格式类 | 用于读取输入数据的类 | TextInputFormat |
| 输出格式类 | 用于写入输出数据的类 | TextOutputFormat |
| Mapper类 | 用于处理输入数据的Mapper类 | MyMapper |
| Reducer类 | 用于处理Map输出数据的Reducer类 | MyReducer |
| 分区器类 | 用于决定数据如何分配到不同Reducer的类 | HashPartitioner |
| 分组比较器类 | 用于比较Map输出键的类 | IntWritable.Comparator |
| 组合比较器类 | 用于比较Map输出键的组合键的类 | CompositeKey.Comparator |
原创文章,作者:未希,如若转载,请注明出处:https://www.kdun.com/ask/1181830.html
本网站发布或转载的文章及图片均来自网络,其原创性以及文中表达的观点和判断不代表本网站。如有问题,请联系客服处理。
发表回复